Claude Opus 4.7 출시 분석: SWE-bench Pro 64.3%, xhigh effort의 의미
Claude Opus 4.7 출시 분석: SWE-bench Pro 64.3%, xhigh effort의 의미
Anthropic이 2026년 4월 16일 Claude Opus 4.7을 일반 공개했습니다. 가격은 그대로, 성능은 전 세대 대비 명백히 올랐습니다. 그런데 단순 "점수 업"이 아니라 사용 방식 자체가 바뀌는 업데이트입니다.
SWE-bench Pro에서 64.3%를 기록했고, Claude Code의 기본 추론 강도가 xhigh로 상향됐으며, /ultrareview라는 새로운 리뷰 전용 커맨드가 들어왔습니다. 이 글에서는 어떤 점이 실제로 달라졌는지, 기존 프롬프트를 바로 써도 되는지, 왜 이번 업데이트가 "세대 교체"에 가까운지 정리합니다.
Claude Opus 4.7란 무엇인가요?
Claude Opus 4.7은 Anthropic이 2026년 4월 16일 출시한 플래그십 코딩/에이전틱 모델입니다. 가격은 Opus 4.6과 동일한 $5/M 입력·$25/M 출력이며, API 모델 ID는
claude-opus-4-7입니다. Claude 제품 전체와 Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry에서 이용할 수 있습니다.
이번 모델은 "일반 공개 중 가장 강한 모델" 포지션을 탈환하기 위해 설계됐습니다. 비공개 프리뷰로 존재하는 Claude Mythos Preview는 여전히 상위지만, 개발자가 실제로 쓸 수 있는 모델 중에서는 4.7이 최상단입니다.
가장 중요한 포인트는 이겁니다. 가격이 올라가지 않았다는 것. Opus 4.6 대비 성능이 명백히 뛰었는데 토큰 단가는 같습니다. 대신 토크나이저가 바뀌어서 동일 입력을 처리할 때 토큰 수가 1.0~1.35배로 변동할 수 있습니다. 이 부분은 뒤에서 다시 다루겠습니다.
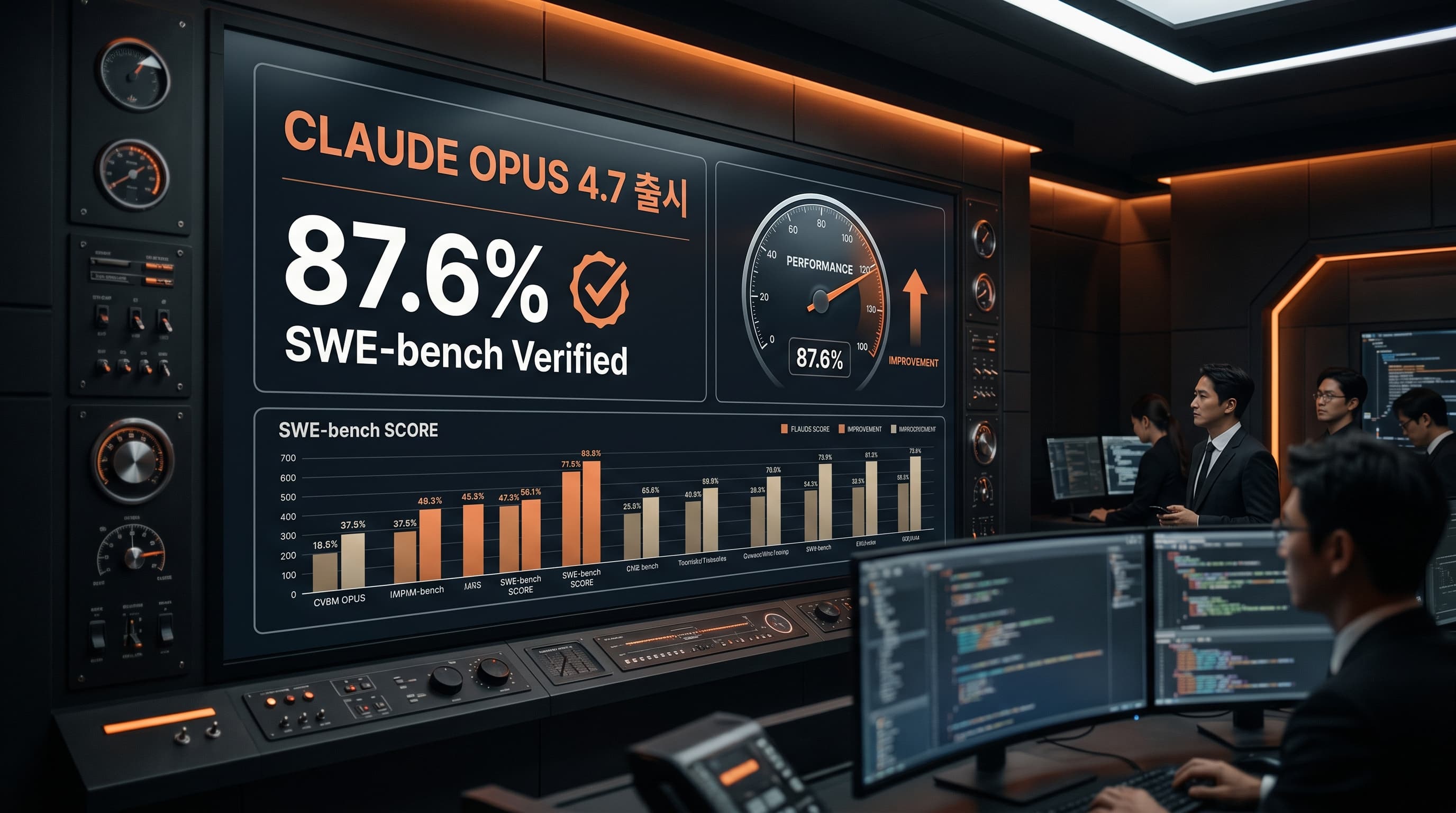
벤치마크로 본 실제 성능 향상
숫자 먼저 보겠습니다.
- SWE-bench Verified: 87.6%
- SWE-bench Pro: 64.3% (Opus 4.6: 53.4%, GPT-5.4: 57.7%)
- CursorBench: 70% (Opus 4.6: 58%)
- XBOW 시각 정확도: 98.5% (Opus 4.6: 54.5%)
- Databricks OfficeQA Pro: 에러 21% 감소
SWE-bench Pro는 실제 프로덕션 레포지토리의 복잡한 버그를 기반으로 만들어진 벤치마크입니다. 단일 파일 수정이 아닌, 여러 파일 간 의존성을 파악해야 풀리는 문제가 많습니다. 여기서 11%p 상승은 "소프트웨어 엔지니어링 전반"에서 능력이 올랐다는 뜻입니다.
프로덕션에서도 동일한 흐름이 확인됐습니다. Rakuten이 자사 SWE-Bench에서 Opus 4.6 대비 태스크 해결률이 3배 증가했다고 공개했습니다. Anthropic 내부 93태스크 코딩 벤치마크에서는 Opus 4.6 대비 13% 향상에, 기존 모델이 풀지 못했던 4개 태스크를 처음으로 해결했습니다.
비전 벤치마크가 특히 주목할 만합니다
XBOW 시각 정확도 98.5%는 오타가 아닙니다. Opus 4.6이 54.5%였으니 약 80% 가까이 뛰어올랐습니다. 이 수치는 컴퓨터 사용 에이전트, 화학 구조 판독, 복잡한 다이어그램 분석 같은 작업에 직접적인 영향을 줍니다. 이미지 장축 최대 해상도도 2,576px(약 3.75MP)로 이전 모델의 3배입니다.
새로 추가된 기능: xhigh, /ultrareview, Auto Mode
벤치마크보다 일상 개발에 더 큰 영향을 주는 건 사실 이 기능들입니다.
xhigh effort: 추론 강도의 새 단계
기존에는 low, medium, high, max 네 단계였습니다. 4.7에서는 high와 max 사이에 xhigh가 추가됐습니다. 추론 품질과 지연 시간 사이를 더 세밀하게 조절할 수 있다는 뜻입니다.
여기서 가장 실질적인 변화는 Claude Code의 기본 effort가 xhigh로 상향됐다는 것입니다. 모든 플랜에서 기본 적용입니다. 사용자가 따로 뭔가 하지 않아도 자동으로 더 깊이 생각하는 쪽으로 바뀝니다.
/ultrareview: 전담 리뷰 커맨드
/ultrareview 슬래시 커맨드는 전용 리뷰 세션을 시작해 버그와 설계 이슈를 플래그합니다. Pro/Max 사용자에게 월 3회 무료로 제공됩니다.
Vercel 팀이 내부 테스트 후 남긴 평가가 인상적입니다. "자기 한계에 대해 더 정직해졌고, 시스템 코드에 대해 증명부터 시작하는 새로운 행동을 보인다"는 코멘트입니다. 코드 리뷰가 인간 시니어보다 꼼꼼하게 작동하는 순간이 생겼다는 의미로 읽힙니다.
Auto Mode, Max 플랜으로 확장
Auto Mode는 이전에 Claude Code 일부 사용자에게만 열려 있던 기능입니다. 이제 Max 플랜 사용자에게도 제공됩니다. Claude가 대신 결정을 내려 긴 작업을 중단 없이 진행합니다.
"위험한 거 아니냐"는 질문이 나올 수 있습니다. 공식 설명으로는 skip-all-permissions 플래그보다 안전한 구조입니다. 파일 쓰기나 명령 실행 같은 민감한 작업에서는 여전히 컨펌을 요청합니다.
Task Budget과 파일시스템 메모리
Task Budget(공개 베타)은 토큰 예산을 Claude에게 알려주면, 모델이 남은 예산을 실시간으로 확인하면서 작업 우선순위를 조정합니다. 예산이 부족해지면 우아하게 마무리합니다. 긴 에이전틱 작업에서 "토큰 다 쓰고 중간에 멈추는" 문제를 해결하기 위한 기능입니다.
파일시스템 기반 메모리는 장기/다중 세션 작업에서 중요 노트를 기억하고 활용하는 능력을 향상시켰습니다. 주간 단위 프로젝트나 여러 번의 세션으로 나눠지는 리팩토링 작업에 특히 유리합니다.
Opus 4.6 vs Opus 4.7: 마이그레이션 가이드
핵심 요약: 가격은 동일하지만 토크나이저가 바뀝니다. 동일 입력이 1.0~1.35배 토큰으로 변환되며, xhigh/max 레벨에서는 사고 길이도 늘어납니다.
max_tokens를 최소 64k로 올리고, 기존 프롬프트는 재튜닝이 필요할 수 있습니다.
Anthropic이 공식 마이그레이션 가이드에서 강조하는 포인트는 크게 세 가지입니다.
1. 토큰 사용량 최대 35% 증가 가능
새 토크나이저는 콘텐츠 유형에 따라 동일 입력을 1.0~1.35배 토큰으로 변환합니다. 코드가 많을수록 증가폭이 큰 경향이 있습니다. 예산을 짠 파이프라인이라면 35%를 버퍼로 미리 잡아두는 것이 안전합니다.
단, 내부 코딩 평가에서는 모든 effort 레벨에서 토큰 사용 효율이 개선됐다는 보고도 있습니다. 입력은 늘어나지만 출력은 동일 품질을 더 짧게 달성할 수 있다는 뜻입니다.
2. max_tokens 상향 필요
xhigh와 max effort에서는 에이전틱 설정 후반 턴에서 출력 토큰이 늘어납니다. 더 깊이 사고하기 때문입니다. 기존 32k 설정이면 잘려나가는 경우가 생길 수 있습니다. 64k 이상으로 올리는 걸 권장합니다.
3. 지시 따르기가 훨씬 엄밀해짐
이게 사실 가장 중요합니다. 4.7은 지시를 "문자 그대로" 실행합니다. 이전 모델이 느슨하게 해석하거나 일부를 스킵하던 부분을 4.7은 전부 지킵니다.
좋은 일 같지만 함정이 있습니다. 기존 프롬프트에 쓰여 있던 암묵적 가정이 드러납니다. "이 정도는 알아서 판단하겠지"라고 생각하고 비워뒀던 부분에서 예상 밖 동작이 나올 수 있습니다. Anthropic은 "기존 프롬프트와 하네스를 재튜닝하라"고 권장합니다.
안전성과 정렬: 무엇이 달라졌나
Claude Opus 4.7의 안전 프로파일은 Opus 4.6과 비슷합니다. 속임수, 아첨, 오용 협력 같은 저빈도 실패 모드는 유사한 수준을 유지합니다. 개선된 영역은 정직성과 악성 프롬프트 인젝션 저항성입니다.
흥미로운 점은 일부러 축소된 기능이 있다는 것입니다. Project Glasswing 맥락에서 공개된 바로는, 4.7은 사이버 공격 역량을 의도적으로 줄인 첫 모델입니다. 대신 합법적인 보안 연구자를 위한 Cyber Verification Program이 새로 마련됐습니다. 취약점 연구, 모의침투, 레드팀 활동을 하는 전문가는 검증 절차를 거쳐 확장된 권한을 받을 수 있습니다.
정렬 평가 결과는 "largely well-aligned and trustworthy, though not fully ideal"로 표현됐습니다. 완벽하지는 않지만 대체로 신뢰할 수 있다는 뜻입니다. 약간 퇴보한 영역은 규제 물질 관련 응답에서 과도하게 상세한 피해 완화 조언을 하는 경향입니다.
초기 테스터들의 반응
출시와 함께 공개된 파트너 코멘트는 모델의 성격을 파악하는 데 도움이 됩니다.
- Replit: "같은 품질을 더 낮은 비용으로. 로그와 트레이스 분석, 버그 찾기, 수정 제안에서 더 효율적이다."
- Vercel: "one-shot 코딩에서 압도적이다. 자기 한계에 대해 더 정직하고, 시스템 코드에 대해 증명부터 시작하는 새로운 행동을 보인다."
- Harvey (법률 AI): "BigLaw Bench에서 high effort 기준 90.9%를 기록했다. 양도 조항 vs 경영권 변동 조항 구분 같은, 프론티어 모델이 어려워했던 작업을 처리한다."
- Notion Agent: "14% 개선되고 도구 에러가 1/3로 줄었다. 암묵적 요구를 테스트하는 케이스를 통과한 첫 모델이다."
- XBOW: "Opus에 대한 최대 불만이 해결됐다. 이전에 사용할 수 없던 전 영역의 작업이 열렸다."
- Cognition/Devin: "몇 시간 동안 일관성 있게 작동하고, 어려운 문제를 포기하지 않는다."
- Genspark: "프로덕션 차별화 핵심 세 가지 — 루프 저항, 일관성, 우아한 에러 복구 — 모두 통과했다."
공통적으로 반복되는 키워드가 있습니다. "정직함", "일관성", "포기하지 않음", "암묵적 요구". 벤치마크 숫자가 아니라 "긴 작업에서 어떻게 행동하느냐"가 개선된 포인트라는 걸 시사합니다.
마무리
Claude Opus 4.7은 "같은 가격, 다른 급"의 업데이트입니다. SWE-bench Pro 64.3%, XBOW 비전 98.5%, xhigh effort 기본화, /ultrareview 커맨드까지. 개별 변화 하나하나가 크진 않아도, 합쳐진 결과는 세대 교체에 가깝습니다.
오늘 저녁에 할 수 있는 실천 항목은 이렇습니다.
- Claude Code 업데이트 후 xhigh 기본 동작을 체감해보기
- 기존 프롬프트 하나를 4.7에서 돌려보고 "엄밀한 지시 따르기"가 어떻게 작동하는지 확인
max_tokens를 64k 이상으로 상향- 복잡한 리팩토링 PR이 있다면
/ultrareview로 한 번 돌려보기
꾸준히 Claude를 써온 개발자라면 4.7은 놓치면 안 되는 업데이트입니다. 새 프롬프트 하나라도 테스트해보시고, 느낀 점을 댓글로 공유해주세요.
자주 묻는 질문 (FAQ)
Q: Claude Opus 4.7은 언제 출시됐나요?
2026년 4월 16일 일반 공개(General Availability)됐습니다. Claude 제품, Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry에서 사용할 수 있으며, 모델 ID는 claude-opus-4-7입니다.
Q: 가격이 올랐나요?
아니요. 입력 $5/M 토큰, 출력 $25/M 토큰으로 Opus 4.6과 동일합니다. 다만 새 토크나이저가 적용되어 동일 입력이 1.0~1.35배 토큰으로 계산될 수 있어, 실질 비용은 케이스에 따라 달라질 수 있습니다.
Q: Opus 4.6 프롬프트를 그대로 써도 되나요?
일부는 그대로 작동하지만, 지시 따르기 엄밀성이 높아져 기존에 "암묵적으로 처리되던" 부분이 예상 밖 동작을 할 수 있습니다. 에이전틱 하네스나 장기 워크플로우 프롬프트는 한 번 테스트 후 재튜닝을 권장합니다.
Q: xhigh effort는 어디서 쓸 수 있나요?
Claude API에서 effort 파라미터로 지정 가능하며, Claude Code는 이미 모든 플랜에서 기본값이 xhigh로 상향됐습니다. 별도 설정 없이 자동 적용됩니다.
Q: /ultrareview 커맨드는 무료인가요?
Pro/Max 사용자에게 월 3회 무료 제공됩니다. 그 이상은 사용량에 따라 과금됩니다.
Q: 4.7과 Claude Mythos Preview는 무엇이 다른가요?
Mythos Preview는 Anthropic이 특정 파트너에게만 비공개로 제공하는 상위 프리뷰 모델입니다. 4.7은 모든 개발자가 API와 제품으로 접근할 수 있는 "일반 공개 중 가장 강한 모델" 포지션입니다.

